

Content from Software Packaging
Last updated on 2024-12-10 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- What is software packaging?
- How is packaging related to reproducibility and the FAIR4RS principles?
- What does packaging a python project look like?
Objectives
- Recognise the importance of software packaging to ensure reproducibility.
- Understand what are the basic building blocks of a Python package.
Introduction
One of the most challenging aspects of research is reproducibility. This necessitates the need to ensure that both research data and research software adhere to a set of guidelines that better enable open research practices across all disciplines. The recent adaptation of the original FAIR principles (Findable, Accessible, Interoperable, Reusable) means that research software can now also benefit from the same general framework as research data, whilst accounting for their inherent differences, including software versioning, dependency management, writing documentation, and choosing an appropriate license.
Discussion
Can you recall a time when you have used someone else’s software but encountered difficulties in reproducing their results? What challenges did you face and how did you overcome them?
Software packaging is one of the core elements of reproducible
research software. In general, software packaging
encompasses the process of collecting and configuring software
components into a format that can be easily deployed on different
computing environments.

Callout
Think about what a package is in general; you typically
have a box of items that you want to post to someone else in the world.
But before you post it for others to use, you need to make sure the
package has things like: an address label, an instruction manual, and
protective material.
Challenge 1: Packaging Analogy
Using the analogy in the callout above, provide an example for each package attribute in terms of the software attribute.
Box of items: The software itself (source code, data, images).
Address label: Installation instructions specifying the target system requirements (operating system, hardware compatibility).
Instruction manual: User documentation explaining how to use the software effectively.
Protective materials: Error handling routines, data validation checks to safeguard the software from misuse or unexpected situations.
Overview of Software Packaging
The purpose of a software package is to install (or deploy) some source code in different systems that can be executed by other users. This has important considerations that you, as the developer, will have to take into account, including:
Target Users: Who are you building this package for? Beginners, experienced users, or a specific domain? This will influence the level of detail needed in the documentation and the complexity of dependencies you include.
Dependencies: What other Python libraries does your package rely on to function? What about hardware dependencies? Finding the right balance between including everything a user may need and keeping the package lightweight is important.
Testability: How will users test your package? Consider including unit tests and examples to demonstrate usage and ensure your code functions as expected.
Once you have thought about candidate solutions for these questions, you will be in a strong position to package your project.
Packaging in Python
The most basic directory structure of a Python package looks something like:
📦 my_project/
├── 📂 my_package/
│ └── 📄 __init__.py
└── 📄 pyproject.toml
where
- 📦 `my_project/` is the root directory of the project.
- 📂 `my_package/` is the package directory containing the source code.
- 📄 `__init__.py` is an initialisation script (note; this also lets Python know that there are importable modules in this directory).
- 📄 `pyproject.toml` is a configuation file for setting up the package, containing basic metadata. Tools such as `setuptools` and `pip` use this script to configure how the package is built, distributed, and installed.Callout
For example, consider the times you have imported a library, such as numpy. The ability to write:
is primarily enabled by the specific (modular) structuring of the
numpy package. This includes presence of the __init__.py
file, which signals to Python that the directory is a package, allowing
to import its content using the import statement. The
complete import numpy statement then means Python searches
for the numpy package in its search path
(sys.path) and loads its contents into the namespace under
the name numpy.
Discussion
Another important point to highlight is the use of the
__init__.py file in Python packages. In versions >= 3.3,
Python introduced the concept of implicit namespace packages (see PEP 420). Namespace
packages are a way of splitting a regular Python package (as described
above) across multiple directories, which ultimately means the
__init__.py file is not required to create a package.
However, namespace packages are not commonly used, and it is common
practise to still include __init__.py script to create
“regular” packages.
Apart from the reasons mentioned above, what other advantages can you
think of that would enable software development best practises by
including the __init__.py script? Can you find out which
kind of projects benefit from namespace packages?
Challenge 2: Improving your project’s packaging
The directory structure of the basic Python package shown above is a good starting point, but it can be improved. From what you have learned so far, what other files and folders could you include in your package to provide better organisation, readability, and compatibility?
A possible improvement could be to include the following to your package:
📦 my_project/
├── 📂 my_package/
│ └── 📄 __init__.py
├── 📂 tests/
├── 📄 pyproject.toml
├── 📄 README.md
└── 📄 LICENSEThe most obvious way to improve the package structure is to include a
series of unit tests in a tests directory to demonstrate
usage and ensure your code functions as expected. The main benefit of a
README.md file is to provide essential information and
guidance about a project to users, contributors, and maintainers in a
concise and easily accessible format. Similarly, the purpose of a
LICENSE.md file is to specify the licensing terms and
conditions under which the package’s code and associated assets are made
available to others for use, modification, and distribution.
Although we have touched on the core concepts of packaging in Python,
including how to set up one using the pyproject.toml
configuration file, we still need to learn about how to write the
metadata and logic for building a package. The next episode of this
course provides a brief overview of the history of Python packaging, and
what is required to turn your own project into a package.
Key Points
Reproducibility is an integral concept in the FAIR4RS principles. Appropriate software packaging is one way to account for reproducible research software, which involves collecting and configuring software components into a format deployable across different computer systems.
Software packaging is akin to the packaging a box for shipment. Attributes such as the software source code, installation instructions, user documentation, and test scripts all support to ensure reproducibility.
The purpose of a software package is to install source code for execution on various systems, with considerations including target users, dependencies, and testability.
Content from Package File History
Last updated on 2024-12-10 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- What is required to turn your Python project into a package?
- Why are there so many file types you can use to create packages in Python?
- Which file type is the most appropriate for my project?
Objectives
- Learn the difference between a python project and package
- Understand the prerequisites for turning your project into a package
- Explain the different ways of creating a Python Package
- Understand the shortfalls of the previous packaging standards
Introduction
In this episode we are going to look at what turns your project of python code into a Python package. Throughout Pythons development there have been many different ways of doing this, we will aim to explore some of these. This is to both build an understanding of why the current standard is what it is and to have some context if you ever come across the other methods when looking at other projects.
What Python packaging files exist?
- requirements.txt
- setup.py
- setup.cfg
- pyproject.toml
Requirements.txt
A requirements.txt is a text file where each line
represents a package or library that your project depends on. A package
managing tool like PIP can use this file to install all the necessary
dependencies.
While a requirements.txt file isn’t normally directly used for packaging, its a simple and common filetype that offers some of the features that the packaging files do.
requests==2.26.0
numpy>=1.21.0
matplotlib<4.0Setup.py
Before the introduction of pyproject.toml the main tool
supported for installing packages was setup.py. As the
extension suggests a setup.py is a python file where the
metadata and logic for building your package are contained.
Setup.py problems
Q: Discuss with each other what problems if any you think there may be with using a python file to create python packages
Hint: Think about the differences between a code file and a text file
Some potential issues are: 1. As setup.py is a code
file, there is a potential for malicious code to be hidden in them if
the file comes from an untrusted source 2. There is quite a bit of
‘boilerplate’ in each file 3. The syntax has to be precise and may be
confusing to those not familiar with Python
Setup.cfg
To tackle some of the problems with setup.py, another
standard file was introduced called setup.cfg (cfg stands
for config).
The task of a setup.cfg file is to declare metadata and
settings required for a package in a simple manner. Unlike a setup.py
which requires code imports and functions, the setup.cfg
only has headers and key value pairs.
Key Value Pair
A key value pair is a fundamental way of storing data which is used across many languages and formats. Here’s how it works:
- Key: Is the unique identifier, like the label on a file in a filing cabinet
- Value: Is the actual data that needs storing. It can be a number, text or many other things.
An example would be name = Jane
[metadata]
name = my_cool_package
description = A package to do awesome things
long_description = file: README.md
author = John Doe
author_email = john.doe@example.com
keywords = data, analysis, python
license = MIT
[options]
# Specify libraries your project needs (dependencies)
install_requires = pandas numpy
# Python version compatibility (optional)
python_requires = >=3.7When using a setup.cfg however, a dummy
setup.py was still required to build the package. This
looked like:
Pyproject.toml
Introduced in (PEP517)[https://peps.python.org/pep-0517/], the latest file for
packaging a python project is the pyproject.toml file. Like
a .cfg file, a toml file is designed to be
easy to read and declarative.
Callout
TOML stands for Tom’s Obvious Minimal Language!
When originally introduced, the pyproject.toml file
aimed to replace setup.py as the place to declare build
system dependencies. For example the most basic
pyproject.toml would look like this.
TOML
[build-system]
# Minimum requirements for the build system to execute.
requires = ["setuptools", "wheel"]Project metadata however was still being specified either in a
setup.py or a setup.cfg, the latter being
preferred.
With the introduction of (PEP621)[https://peps.python.org/pep-0621/] in 2020, project
metadata could also be stored in the pyproject.toml files,
meaning you only now need the single file to specify all the build
requirements and metadata required for your package! This is still the
preferred way in the community.
We will be going into how to make a pyproject.toml file
in more detail in one of the next episodes.
Content from Accessing Packages
Last updated on 2024-12-10 | Edit this page
Estimated time: 32 minutes
Overview
Questions
- What are the different ways of downloading python packages?
- What are package managers?
- How can I access my own package?
Objectives
- Learn about package managers such as PIP
- Install packages using PIP
- Install packages from source
Introduction
Due to Pythons popularity as a language, it is quite likely that you won’t be the first person to set off on solving any particular task. Many others have worked on common problems and then shared their solution in the form of a package, which you can conveniently integrate into your own code and use!
Popular Packages
Some of the most popular packages you may have heard of are:
- Numpy
- Pandas
- Tensorlow
- Matplotlib
- Requests
To use a package that is installed you use the key word
import in python.
Python Package Index (PyPI)
The Python Package Index or PyPI is an online repository of Python packages hosting over 500,000 packages! While there are alternatives such as conda-forge, PyPI is by far the most commonly used and likely to have all you need.
Exercise 1: Explore PyPI
Explore PyPI to get familiar with it, try searching for packages that are relevant to your research domain / role!
pip
pip (package installer for Python) is the standard tool for installing packages from PyPI. You can think of PyPI being the supermarket full of packages and pip being the delivery van bringing it to you.
Using pip
pip itself is a python package that can be found on PyPI. It however comes preinstalled with most python installations, for example python.org and inside virtual environments.
The most common way to use pip is from the command line. At the top of a package page on PyPI will be the example line you need to install the package
py -m pip install numpyThe above will install numpy from PyPI, a popular scientific computing package enabling a wide range of mathematical and scientific functions.
Exercise 2: Create venv and install Numpy
Step 1: Create a venv in the .venv directory using the command
py -m venv .venv and activate it with
Step 2: Install Numpy into your new environment
Step 3: Check your results with py -m pip list
Step 4: Deactivate your environment with deactivate
Check out this documentation or the FAIR4RS course on virtual environments to learn more!
pip can also be used to install packages from source. This means that
the package file structure (source) is on your local computer and pip
installs it using the instructions from the setup.py or
pyproject.toml file. This is especially handy for packages
either not on PyPI, like ones downloaded from github, or for your own
packages you’re developing.
py -m pip install .The above command should be universal on both windows and mac/unix setups. It may be worth checking with the class at this point that they are all familiar with the -m notation, and what the above command does exactly
Here the . means to install your current directory as a
Python package. For this to work the directory your command line
interface is currently in needs to have a packaging file,
i.e. setup.py or pyproject.toml.
Key Points
- pip can be used to download and install Python packages
- PyPI is an online package repository which pip downloads from
- pip can also install local packages like your own
Content from Creating Packages
Last updated on 2024-12-10 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- Where do I start if I want to make a Python package?
- What will I need / want in my package?
- What’s considered good practice with packaging?
Objectives
- Create and build a basic example Python package
- Understand all the parts and decisions in making the package
Introduction
This episode will see us creating our own Python project from scratch and installing it into a python virtual environment ready for use. Feel free if you’re feeling adventurous to create your own package content or follow along with this example of a Fibonacci counter.
Fibonacci Counter
This package will allow a user to find any value from the Fibonacci
sequence. The Fibonacci sequence is a series of whole numbers where each
number is the sum of the two previous numbers. The first 8 numbers of
the sequence are 0, 1, 1, 2, 3, 5, 8, 13.
Reinventing the wheel
It is good to ask yourself if the package or features you are designing have been done before. Obviously we have chosen a simple function as the focus of this episode is on packaging code rather than developing novel code.
Creating the package contents
In this section we will go through creating everything required for the package.
What files and content go into a package?
Think back to the earlier episodes and try to recall all the things that can go into a package.
- Python Module - This is the directory with the python code that does the work.
- Configuration File - e.g. your pyproject.toml file
- Other metadata files - e.g. LICENCE, README.md, citation.cff
- Python Tests - A directory full of unit-tests and other tests
In this episode we will only be creating a minimal example so many of
the files you have thought of won’t be included. Next we will be
creating our directory structure. In either your documents
folder if you are on Windows or your home directory if you
are on macOS or Linux, create a folder called
my_project
📦 my_project/
├── 📂 my_package/
│ └── 📄 fibonacci.py
├── 📄 pyproject.toml
└── 📂 tests/
└── 📄 test_fibonacci.pyThe first thing we will do in this project is create the python module (the actual code!).
Creating Python module
- Create a python file called
fibonacci.pyas shown in the structure above. - Add the following code which contains a function that returns the Fibonacci sequence
Using your Python module
Create a script in your project directory that imports and uses your fibonacci script. This will serve as a good quick test that it works.
Configuration File
In this section we are going to look deeper into the
pyproject.toml. Sections in a .toml file are
called tables. In a pyproject.toml file there are 2 tables
required for a minimum working pyproject.toml: a
[build-system] table and a [project] table.
Take a look at the minimum example pyproject.toml
below.
TOML
[build-system]
requires = ["setuptools"]
[project]
name = "my_cool_package"
version = "0.0.0"
description = "A package to do awesome things"
dependencies = ["pandas", "numpy"][build-system]
The [build-system] table specifies information required
to build your project directory into a package. The main key in this
table is requires, this key states what build tool(s)
should be used to do this building. There are multiple popular build
tools that can be used to build your project, in this tutorial we
will use setuptools, as it is simple and very popular.
[project]
The [project] table is where your package’s core
metadata is declared.
pyproject.toml documentation
The full list of accepted keys can be found here in the documentation
Create your configuration file
Create a pyproject.toml file with the two required
tables. In the [project] table include the following
keys:
- name
- version
- description
- authors
- keywords
Running py -m pip install . will install your package.
Just ensure your terminal’s working directory is the same as the
pyproject.toml file!
Editable Install
When installing your own package locally, there is an option called
editable or -e for short.
py -m pip install -e .
With a default installation (without -e), any changes to your source package will only appear in your python environment when your package is rebuilt and reinstalled. The editable option allows for quick development of a package by removing that need to be reinstalled, for this reason it is sometimes called development mode!
Key Points
- A package can be built with as little as 2 files, a python script and a configuration file
- pyproject.toml files have 2 key tables, [build-system] and [project]
- Editable instals allow for quick and easy package development
Content from Versioning
Last updated on 2024-12-10 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- Why is versioning essential in software development? What problems can arise if versioning is not properly managed?
- How can automation tools, such as those for version bumping, improve the software development process?
- Why is it important to maintain consistency and transparency in software releases?
Objectives
- Explain why versioning is crucial for software development, particularly in maintaining reproducibility and ensuring consistent behaviour of the code after changes.
- Understand how to use tools like Poetry and Python Semantic Release for automating the version bumping process in Python projects.
- Be able to create and integrate custom scripts or CI/CD pipelines for automated version bumping based on commit messages and predefined rules.
Introduction
In previous episodes, we developed a basic Python package to demonstrate the importance of software reproducibility. However, a crucial question that we haven’t addressed yet is: how can we, as the developers, ensure that a change in our package’s source code does not result in the code failing or behaving incorrectly? This is also an important consideration for when you are releasing your package.
Discussion
One of the pitfalls of packaging is to fall into poor naming
conventions, even for scripts. For instance, how many times have you
worked on scripts that was named my_script_v1.py or
my_script_final_version.py? What were your main challenges
with this approach, and what alternative solutions can you think of to
circumvent this naive approach?
Semantic Versioning

The answer the question above is based on a concept called
versioning. Versioning is the practice of assigning unique
version numbers to different states or releases of a given package to
track its development, improvements, and bug fixes over time. The most
popular approach for Python packaging is to use the Semantic Versioning framework, and can be
summarised as follows:
Given a version number X.Y.Z, where X is the major version, Y is the minor version and Z is the patch version, you increment:
X when you make incompatible API changes,
Y when you add functionality in a backwards compatible manner,
Z when you make backwards compatible bug fixes.
API
An Application Programming Interface (API) is the name given to the way different programs or parts of a program to communicate with each other. It provides a set of functions, methods that can be used to interact with a piece of software or data services. Commonly, APIs are used within web-based applications to enable users to receive information from a given service, such as logging into social media accounts, creating weather widgets, or finding geographical locations.
The first version of any package typically starts at 0.1.0, and any
changes following the semantic versioning rules above results in an
increment to the appropriate version numbers. For example, updating a
software from version (0.1.0) to (1.0.0) is called a
major release. Version (1.0.0) is commonly
referred to as the first stable release of the package.
An important point to highlight is the semantic versioning guidance above is a general rule of thumb. Exactly when you decide to bump the versions of your package is dependent on you, as the developer, to be able to make that decision. Developers typically take the size of the project into account as a factor; for example, small packages may require a patch release for every individual bug that is fixed. On the other hand, larger packages often group multiple bug fixes into a single patch release to help with tractability because making a release for every fix would accumulate in a myriad of releases, which can be confusing for users and other developers. The table below shows 3 examples of major, minor and patch releases developers made for Python.
| Release Type | Version Change | Description |
|---|---|---|
| Major Release | 2.0.0 to 3.0.0 | Introduced significant and incompatible changes, such as the print function and new syntax. |
| Minor Release | 3.7.0 to 3.8.0 | Added new features like the walrus operator and positional-only parameters, backward-compatible. |
| Patch Release | 3.8.0 to 3.8.1 | Fixed bugs and made performance improvements without adding new features or breaking changes. |
Pre-release Versions
Pre-release versions in semantic versioning are versions of the software that are still in development or testing before a stable release. They are denoted by appending a hyphen and a series of dot-separated identifiers to the version number, such as 1.0.0-alpha or 1.0.0-beta.1. These versions allow developers to release early versions for testing and feedback while clearly indicating their status.
Callout
Once we publicly release a version of our software, it is crucial to maintain consistency and avoid altering it retroactively. Any necessary fixes needs to be addressed through subsequent releases, typically indicated by an increment in the patch number. For instance, Python 2 reached its final version, 2.7.18, in 2020, more than a decade after the release of Python 3.0. If the developers decided to discontinue support for an older version, leaving vulnerabilities unresolved, they would have to transparently communicate this to their users and encourage them to upgrade.
Challenge 1: Semantic Versioning Decision Making
Imagine you are a developer working on a Python library called
DataTools, which provides various utilities for data
manipulation. The library uses semantic versioning and is currently at
version 1.2.3. You have implemented a new feature that adds support for
reading and writing CSV files with custom delimiters.
According to semantic versioning, should you bump the version to
1.3.0, 1.2.4, or 2.0.0? Explain
your reasoning.
Think about whether the new feature introduces any breaking changes for existing users.
According to semantic versioning, since the new feature adds
functionality in a backward-compatible manner, the version should be
bumped to 1.3.0. This signifies a minor version
increase.
Tools for Version Bumping
At this point, you might be thinking; “Do I have to manually
update the version number in of my package every time I release a new
version?” Thankfully, the answer is no. Often, the version
number associated to your package will typically be in multiple
locations within your project, for example, in your .toml
file and separately in your documentation. This means that manually
updating every location for every release you have can be extremely
cumbersome and prone to human-error, and therefore, you should avoid
manually updating your versions. There are several tools that can help
you manage updating your package versions.
1. Poetry
Poetry is a dependency
management and packaging tool for Python projects. It aims to simplify
the process of managing dependencies, packaging projects, and publishing
them to online repositories. For this, you will have to decide what
release type (major, minor patch) reflects the changes in your source
code. For projects that are managed by Poetry, the version number is in
your pyproject.toml file. For instance, your
pyproject.toml file may look like:
TOML
[tool.poetry]
name = "my_project"
version = "0.1.0"
description = "A simple example project"
authors = ["Your Name"]Once you have decided on the type of release (e.g. patch), you can simply run:
This bumps the version in your toml file from 0.1.0 to 0.1.1, and
changes your .toml file to:
TOML
[tool.poetry]
name = "my_project"
version = "0.1.1"
description = "A simple example project"
authors = ["Your Name"]Callout
Like a venv, Poetry also enables creating virtual
environments, but it provides a more comprehensive toolset for
dependency and environment management, especially when it comes to
packaging and reproducibility. For instance, Poetry’s
poetry.lock file ensures that exact versions of
dependencies are used across different environments. This is one way
research software reproducibility can be maintained.
2. Python Semantic Release
Python Semantic Release is a tool that can automatically bump versions based on keywords found in commit messages using Git. The core idea is to use a standardised commit syntax that allows the tool to parse and automatically determine how to increment the version number. The default commit syntax used by Python Semantic Release is the Angular commit style, which has the following form:
<type>(optional scope): brief overview in present tense
(optional body: explains motivation for the change)
(optional footer: note BREAKING CHANGES here, and issues to be closed)
The tag <type> highlights the kind of change that
is being made. Examples of this include feat for a new
feature, fix for a bug fix, docs for
documentation changes and so on. For more information, please refer to
the Angular commit style documentation.
The (optional scope) is a keyword that provides
additional context for where the change was made in your code base. It
can relate to any information in your development workflow, such as the
function or module that was changed.
Putting this together, once you have git added your file(s), a commit message that would trigger Python Semantic Release to bump your package from version 1.1 to version 1.2 due to a new feature could look something like:
Once you have committed, you can run
$ semantic-release version in your terminal to detect the
semantically correct next version that should be applied to your
project, or $ semantic-release publish to publish to your
choice of version control system (e.g. GitHub).
3. Creating your own Versioning Tool
You can also create your own custom version bump tool using
continuous integration (CI) / continuous deployment (CD) pipelines on
various version control systems (such as GitHub) to automate your
package’s versioning. For instance, you might develop a custom script
that is executed to analyse commit messages, and whenever a push is made
to the remote repository, the CI/CD pipeline is triggered. The script
can parse the commit messages and determines the type of changes made
(e.g., new features, bug fixes, maintenance tasks). Based on predefined
rules, it decides whether to increment the major, minor, or patch
version. Once the script determines the appropriate version bump (major,
minor, or patch), you can specify where to update the version number in
the project’s configuration files (e.g. pyproject.toml,
/docs, /tests, and so on.). After updating the
version number, the script would create a new commit with the updated
version number. Ultimately, the script tags the commit as the new
release version. This tag can be used for referencing specific releases
in the future.
Callout
As a reminder, Continuous Integration/Continuous Deployment is a software development practice that involves automating the process of integrating code changes into a shared repository (CI) and then automatically deploying those changes to production or other environments (CD). GitHub Actions is a common example of a CI/CD tool, which allow developers to seamlessly automate workflows directly within their GitHub repositories.
Challenge 2: Version Bumping your Package
Following the instructions above, install Poetry and use
this to update your Fibonacci package you have build based on the
changes you have made to your code.
Simply run:
$ pip install poetry- Make changes to your code
- Run
$ poetry version minorto change the minor version number to reflect the changes in your code.
Key Points
Versioning is crucial for tracking the development, improvements, and bug fixes of a software package over time. It ensures that changes are documented and managed systematically, aiding in reproducibility and reliability of the software.
Tools like Poetry and Python Semantic Release help automate the version bumping process, reducing manual errors and ensuring that version numbers are updated consistently across all project files.
Once a version is publicly released, it should not be altered retroactively. Any necessary fixes should be addressed through subsequent releases.
Content from Publishing Python Packages
Last updated on 2024-12-10 | Edit this page
Estimated time: 12 minutes
Overview
Questions
- How can you prepare your software for releasing and publishing on different platforms?
- How can GitHub’s automation tools help with publishing your software?
- What are the benefits of publishing your software on PyPI and ORDA?
Objectives
- Understand the significance of releasing and publishing your software in the context of FAIR4RS.
- Learn how to publish your software to PyPI and The University of Sheffield’s ORDA repository.
Preparing to Publish
Now that we have covered the fundamentals of packaging in Python, we can start preparing to publish the package online for others to use. But before we do, we need to make sure our package contains the necessary files. To recap, let’s review the basic directory we created back in episode one, which had the following structure:
📦 my_project/
├── 📂 my_package/
│ └── 📄 init.py
├── 📂 tests/
├── 📂 docs/
│ └── 📄 documentation.md
├── 📄 pyproject.toml
├── 📄 README.md
└── 📄 LICENSEREADME
Firstly, all packages must contain a README.md file that
explains what the project is. how users can install it and how they can
use it. A good example of a README.md file may look
something like:
# My Python Project
My Python Project is a simple utility tool designed to perform basic operations on text files. Whether you need to count words, find specific phrases, or extract data, this tool has you covered.
## Installation
You can install My Python Project via pip:
$ pip install my-python-project
## Usage
from my_python_project import text_utils
text = "Lorem ipsum dolor sit amet, consectetur adipiscing elit."
word_count = text_utils.count_words(text)
print("Word count:", word_count)
This will output:
Word count: 9
Notice that the README.md should be included at the top
level of our project directory. If your package was created using a
.toml file, it should also be included in the metadata by
adding in the following line:
Callout
In the README.md file, developers also usually include
in a “contributing” section for new users that are typically outside of
the project. The purpose of this section is to encourage new developers
to work on the project, while ensuring they follow the etiquette set by
the project developers. This may look something like:
### Contributing
Contributions to My Python Project are welcome! If you'd like to contribute, please follow these steps:
1. Fork the repository.
2. Create a new branch for your feature (git checkout -b feature/new-feature).
3. Make your changes and ensure tests pass.
4. Commit your changes (git commit -am 'Add new feature').
5. Push to the branch (git push origin feature/new-feature).
6. Create a new Pull Request.Licensing
Following this, it is essential for your software to have a license to emphasise to users what their rights are in regards to usage and redistribution. The purpose of this is to provide the developer with some legal protections, if needed. There are many different open source licenses available, and it is up to the developer(s) to choose the appropriate license. You can explore alternative open source licenses at www.choosealicense.com. It is important to note that your selection of license may be influenced by the licenses of your dependencies.
The most common license used in open source projects is the MIT license. The MIT license is permissive, which allows users to freely use, modify, and distribute software while providing a disclaimer of liability.
Callout
The MIT License has the following terms:
Copyright (c)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
As with the README.md, you can also add the license to
your pyproject.toml file as:
Creating Releases of your Software
Once you have prepared all of the material above, you will be in a
good position to release your software to an online repository. The most
common platform to host your software packages is on GitHub, which uses
git as the underlying tool to version control your code
(note; alternatives are GitLab, BitBucket and SourceForge).
While the terms releasing and publishing
are commonly used interchangeably, in this course,
releasing refers to making a version of the software
available for download and use, whereas publishing refers
to the formal announcement and distribution of the software to a wider
audience on a platform or marketplace.
Manual Releasing using Git Tags
On GitHub, it is a relatively simple process to create a release of
your software by using Git tags. Git tags are
a way of permanently tagging a specific point in your repository’s
history, which can be used to denote a version that is suitable for
others to use. A tag is an immutable reference to a commit (or series of
commits), making it simple to identify specific versions of a software,
and the tags are commonly identified in conjunction with the Semantic
Versioning framework (e.g. v1.0.0). For more information about how
GitHub uses tags for software releases, see releases.
In general, tagging a release is a 2 step process using Git:
Create a tag of a specific point in your software package’s history using the
git tagcommand that is denoted by a specific version, and upload it to your remote repository usinggit push.Based on your tag, create a release on GitHub of the relevant files in your repository (usually a zip or tar.gz file), which allows users to download the specific release of your software that corresponds to the time you created your tag.
Collectively, the 2 steps process would look something like:
Once you’ve pushed your tag, you can create a release with the tag you pushed to your remote repository by the following:
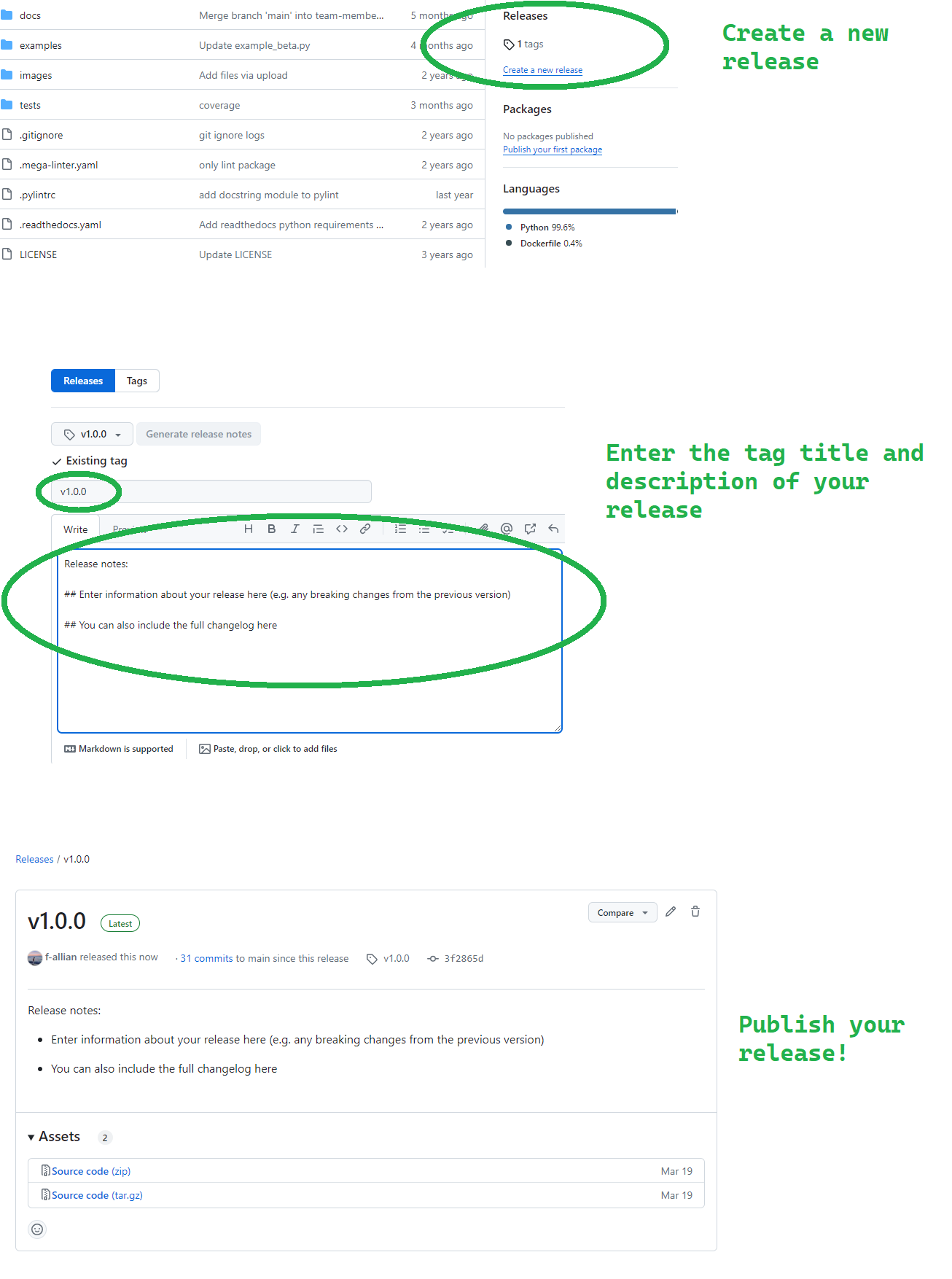
Deleting a Release
You can also delete a release if you make an error using the following commands:
The first line simply deletes the tag v1.0.0 in your
local repository, whereas the second line deletes the
v1.0.0 tag from the remote repository named origin. Note
that the colon indicates that you are not pushing any new content to
replace the tag; instead, you are specifying that the tag should be
deleted. Once you have ran the lines above, you will receive
confirmation that the tag has been deleted.
Challenge 1: Should you always delete a release?
Why might it not be advisable to delete a tag or release, and what alternative actions could you consider instead?
Think about the impact of deleting a tag or release in version control. How might you preserve historical data while managing updates to tags and releases?
Deleting a tag or release in a version control system can disrupt historical tracking and cause confusion for current and future collaborators. Instead of outright deletion, consider tagging the correct commit with a new version number or marking the tag as deprecated with clear documentation. This maintains historical integrity while clarifying the correct state of the codebase. Additionally, communicating changes effectively with team members ensures everyone understands the correct usage of tags and releases for your project.
Automated Releases using Actions
Before wrapping up this section, it is important to highlight that you can also automate your releases on GitHub using Actions, saving you time and helping you release new versions of your package quickly. Since GitHub Actions is a CI/CD platform that allows developers to automate certain aspects of their workflows (such as builds, tests, deployments), we can also configure a release pipeline that is defined by a workflow file (in YAML format) that run whenever a change is made to your repository.
Callout
Recall that GitHub uses the .github directory to store
configuration files that are specific to GitHub features and
integrations, and keeps the repository organised by separating these
files from the main source code. Notice that it is common convention
that the .github folder is a hidden directory.
The .github/workflows directory is the designated place
where GitHub looks for workflow files. By placing your workflow files in
.github/workflows, you enable GitHub Actions to
automatically detect and run the workflows based on the triggers you
specify (such as a push, pull request, or tag creations).
Callout
As a reminder, here are some of the common variables used in GitHub Actions workflow files:
| Variable | Description |
|---|---|
name |
Specifies the name of the workflow. It helps identify the workflow in the GitHub Actions UI and in logs. |
on |
Defines the event that triggers the workflow, such as
push, pull_request, schedule, or
custom events like workflow_dispatch. |
jobs |
Contains one or more jobs to be executed in parallel or sequentially. Each job represents a set of steps that run on the same runner. |
runs-on |
Specifies the type of machine or virtual environment where jobs will
run, such as ubuntu-latest, windows-latest, or
macos-latest. |
steps |
Defines the sequence of tasks to be executed within a job. Each step
can be a shell command, an action, or a series of commands separated by
newlines (run). |
env |
Sets environment variables that will be available to all steps in a job. |
with |
Specifies inputs or parameters for an action or a specific step. |
uses |
Specifies the action to be used in a step. It can refer to an action in a public repository, a published Docker container, or a specific path in the repository. |
id |
Specifies a unique identifier for a step or action output, which can
be referenced in subsequent steps or actions
(outputs). |
secrets |
Allows access to encrypted secrets, such as
GITHUB_TOKEN, which is automatically generated and scoped
to the repository, used for authenticating GitHub API requests. |
There are several workflow extensions already present on GitHub that you can use in your configuration file to automate your releases (e.g. action-gh-release). An example workflow file to automatically trigger a new release based on a push could look something like:
YAML
name: Create Release
on:
push:
tags:
- 'v*' # Trigger on tags starting with 'v'
permissions:
contents: write # Ensure write permissions for the workflow
jobs:
release:
name: Create GitHub Release
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2 # Checkout the repository's code
- name: Create Release
uses: softprops/action-gh-release@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # Pass GitHub token to the action
with:
tag_name: ${{ github.ref }} # The full tag name, e.g., refs/tags/v1.0.0
release_name: Release ${{ github.ref }} # Release name based on the tagLet’s break down what is happening in the above workflow file.
The first logic
on.push.tags - 'v*'ensures the workflow triggers only when a tag starting with v is pushed, which is in line with the Semantic Versioning framework. Following this, we ensure that the workflow has the relevant write permissions to execute the workflow.Next, after initiating the operating system environment (
ubuntu-latest) there are 2 separate steps within the job that are carried out: first,Checkout codeuses theactions/checkout@v2action to fetch the repository’s code into the workflow environment. Second,Create Releaseuses thesoftprops/action-gh-release@v1action to automate the creation of a GitHub release. TheGITHUB_TOKENenvironment variable, securely provided through GitHub secrets (${{ secrets.GITHUB_TOKEN }}), allows the action to perform repository operations like creating releases. The action is configured with inputs such astag_nameandrelease_name, derived dynamically from the Git tag (${{ github.ref }}), ensuring each release is appropriately named and described (body: Automated release created by GitHub Actions.).
Ultimately, a workflow like this streamlines the process of managing
releases by automating tasks that would otherwise require manual
intervention as we have demonstrated above. Once you have created a file
similar to the one above, you can view the status of the workflow in the
Actions tab as usual.
Challenge 2: Automating Releases
You have been tasked with setting up a GitHub Actions workflow to
automate the release process whenever a tag is pushed to your
repository. Despite configuring the workflow correctly
(on: push: tags: - 'v*'), you notice that the release is
not being created. Provide a systematic approach to troubleshoot and
resolve this issue.
Does GitHub provide a way to view the output logs for a given workflow?
There are several different approaches to debug this workflow. The
first place to check would be the output log files from the workflow for
any errors or warnings related to event triggers - this will give you a
good idea where in your file the error may be arising. Since the error
in question is likely due to the push itself, the most obvious line to
check is on: push: tags: - 'v*' to ensure it correctly
triggers on tag pushes starting with v, and ensure Semantic
Versioning practices are being followed, and that there are no
typographical errors. The second most common fault is that the GitHub
token (secrets.GITHUB_TOKEN) used in your workflow has been
incorrectly inputted, and/or may have insufficient permissions
(permissions: contents: write) to create releases and
perform other necessary actions in your repository.
Callout
Remember to never publish any sensitive information, such as passwords, directly on GitHub. Storing sensitive data in your repository makes it publicly accessible (if your repository is public) or easily accessible to anyone with repository access (if private). This can lead to unauthorized access, security breaches, and potential misuse of your code. Instead, use should use GitHub Secrets or environment variables to securely manage the sensitive information, ensuring it is kept safe and only accessible by authorised collaborators or workflows.
Publishing your Software
Python Packaging Index
Now that we have covered how to release specific versions of your
software, we will turn to how to publish your package on an online
repository that allows others to easily install and use you software. PyPI (or the Python Packaging Index) is the
official package repository for the Python community. It serves as the
central location where developers can publish and share their packages,
making them easily accessible to the wider community. When we use
pip to install packages from the command line, it fetches
them from PyPI by default. Uploading your packages to PyPI is
recommended if you want to distribute your projects widely, as it allows
other developers to easily find, install, and use your software.
Callout
Developers often use TestPyPI for testing and validating packages before they are officially published on PyPI.
To build the wheels, there are 2 tools that we need to install and
use. The first is build, which is a command-line tool used
to build source distributions, and wheel distributions of Python
projects based on the metadata specified in the
pyproject.toml. On the other hand, twine is
the tool we use to securely upload the built distributions to PyPI,
which handles tasks like authentication and transfer of package
files.
In practice, the installation and usage of these tools would look something like:
This will create dist/your-project-name-1.0.0.tar.gz
(source distribution) and
dist/your-project-name-1.0.0-py3-none-any.whl (wheel
distribution) in the dist directory. Next, we can use twine
to securely upload the built distributions to PyPI:
We can also run:
BASH
# Check our files is ready to be uploaded using twine check
twine check dist/*
# Check our package is ready to be uploaded to TestPyPI
twine upload --repository testpypi dist/*Once we have confirmed that everything works as expected on TestPyPI, we may proceed with installing our package to PyPI:
Finally, once our package is available on PyPI this means that other users can install the package using the command:
Challenge 3: Automate Publishing to PyPI
You would like to automate the process of publishing a Python package to PyPI whenever a new tag is pushed to your GitHub repository. Describe how you would set up a GitHub Actions workflow to achieve this automation. Include steps to handle versioning, build the package, securely manage PyPI credentials, and ensure proper error handling.
We can start by configuring a GitHub Actions workflow (e.g.,
publish.yml) triggered specifically on tag pushes as demonstrated in the
previous section (on: push: tags: - 'v*'). Within the
workflow, we can define jobs to build the package using tools like
build (python -m build) to create both
sdist and the wheel distributions. Following
this, we securely manage our PyPI credentials by storing them as GitHub
Secrets (secrets.PYPI_USERNAME,
secrets.PYPI_PASSWORD) and only access them securely within
the workflow environment.
Following this, we use twine to handle the upload
(twine upload dist/*) of the prepared distributions to
PyPI. We can also implement appropriate error handling mechanisms
(e.g. using try...catch) within the workflow to manage
unexpected issues and ensure notifications are set up to provide status
updates.
Publishing to ORDA
At The University of Sheffield, researchers also use another popular
repository called ORDA.
ORDA is the University of Sheffield’s main research data repository,
facilitating the sharing, discovery, and preservation of the
university’s research data. Managed by the University Library’s Research
Data Management team and provided by Figshare, ORDA assigns a DOI
(Digital Object Identifier) to each deposited record, ensuring its
accessibility and citability. Researchers are encouraged to use ORDA
unless a subject-specific repository or data center is more commonly
used in their field. ORDA supports the FAIR principles, and by extension
the FAIR4RS principles, by making research outputs citable,
discoverable, and easily accessible to a wider research community. As
with PyPI, you should first sign up to ORDA (note; you should use your
university credentials to create your account).
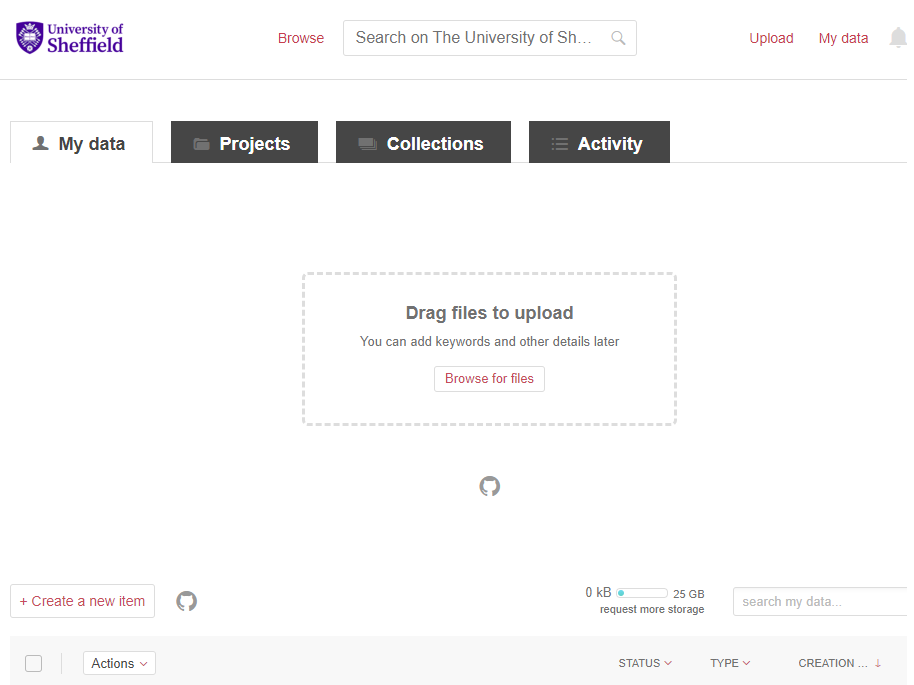
Figure 3 demonstrates how to upload your project to ORDA using their graphical user interface functionality. There is also the option to connect your project’s GitHub account to ORDA, allowing further portability between the two platforms. Once you have published your software on ORDA, it is readily available for other researchers to use and cite in their own research.
Challenge 4: DOI and Reproducibility
In a research context, why is it important to cite software releases via a DOI for example, alongside academic papers?
Citing software releases via a DOI alongside academic papers in research is crucial for several reasons. Firstly, it enhances reproducibility by providing clear references to the specific versions of software used in research. This allows other researchers to replicate and verify findings, ensuring the reliability of published results. Secondly, it promotes transparency by documenting the tools and methods used in studies, which is essential for research validation and building upon existing work. Also, citing software releases acknowledges the contributions of software developers and teams, ensuring they receive proper credit for their work, much like authors of academic papers.
Another useful integration feature ORDA enables is the use of their API, which allows developers to further automate their software publishing. As with the example above using PyPI, we can also use GitHub to create a CI/CD workflow that triggers a release to ORDA once we have officially published a release of our software. An example file for this workflow could look something like:
YAML
name: Upload to ORDA
on:
release:
types: [published]
jobs:
upload:
runs-on: ubuntu-latest
steps:
- name: Prepare Data Folder
run: mkdir 'data'
- name: Download Archive
run: |
curl -sL "${{ github.event.release.zipball_url }}" > "${{ github.event.repository.name }}-${{ github.event.release.tag_name }}.zip"
curl -sL "${{ github.event.release.tarball_url }}" > "${{ github.event.repository.name }}-${{ github.event.release.tag_name }}.tar.gz"
- name: Move Archive
run: |
mv "${{ github.event.repository.name }}-${{ github.event.release.tag_name }}.zip" data/
mv "${{ github.event.repository.name }}-${{ github.event.release.tag_name }}.tar.gz" data/
- name: Upload to Figshare
uses: figshare/github-upload-action@v1.1
with:
FIGSHARE_TOKEN: ${{ secrets.FIGSHARE_TOKEN }}
FIGSHARE_ENDPOINT: 'https://api.figshare.com/v2'
FIGSHARE_ARTICLE_ID: YOUR_ID_NUMBER
DATA_DIR: 'data'The file above is tailored for uploading data to ORDA upon triggering
by a published release event. It begins by preparing a data folder,
downloading the archive associated with the release tag, moving the
downloaded files to the data directory, and finally using the
figshare/github-upload-action integration to upload the
data to ORDA using the specified token, endpoint, article ID, and data
directory. Note, you can create your own personal Figshare token in your
account settings. Importantly, remember that as with the PyPI username
and password, your Figshare token is sensitive and must be passed in as
a secret or environment variable.
Finally, once you have uploaded your file sources to ORDA, your software will be readily available for other researchers to use, allowing significant progress towards building a transparent and reproducible research software environment for all involved.
Key Points
GitHub tags provide a way to manage specific software versions via releases, enabling developers to easily reference and distribute stable versions of their software for their users.
You can easily publish your package on PyPI for the wider Python community, allowing your users to simply install your software using
pip install.The University of Sheffield’s ORDA repository is another valuable platform to upload your software, further enabling software reproducibility, transparency, and research impact for all project collaborators involved.